As an intern, or in your spare time perhaps, were you ever given the unenviable responsibility of collecting data from a website into a different output, like a table or list?
Say, for example, you want to gather the different titles and prices, along with other details, of books sold on an online book store. Let’s take a look at a simple online book store online.

One way to do this would be to open your output format straightaway, say an excel file, and start the arduous task of copying all the details you need and pasting them into a spreadsheet.
You might end up with something like this:

But what if you wanted the information of ALL the books sold on this website by the book store? Do you have what it takes to click through ALL FIFTY pages of this book store to gather all of this information into a list? Worse still, what if the details you’re looking for are not on the category page? Imagine if you had to traverse through 50 x 20 = 1000 (ONE THOUSAND!) product pages to get all the information you need?
No one should have to manually complete such a task. This is where automated Web Scraping comes in handy.
What exactly is web scraping?
Web scraping is a technique used to extract data, mostly in text form but could also be in other formats, from a website into a database or spreadsheet. This can either be done manually, as described in the long and tedious process above, or can be automated with the help of a programming language like Python, and library resources for configuring and implementing our requirements.
Web scraping is a great tool that can be used to extract different types of information online such as:
- tracking daily changes in stock prices
- price comparisons for a product
- social media posts (tweets, IG/FB posts) etc.
The process of web scraping can be broadly categorized as involving 3 separate steps: requesting, parsing and saving output. The first step in web scraping, requesting, involves sending a request to the webpage server and grabbing the response. By grabbing the response from the server, which contains all the information on the website, we can break down the website into its composite elements (in the case of a simple website, these elements are the HTML tags that form the basis of a website). Breaking down the website into its elements makes it easy to search within the website and extract the data we need. That is the parsing step. The final step, saving output, involves saving all the required information extracted and dumping them into the file or format that fits the required deliverable.
To add some context to these processes, let’s try to automate the process of web scraping this simple online book store.
Project
Use a programming language to create a simple web scraper that scrapes the basic details of books sold on the website and saves the details into a .xlsx or .csv file.
Solution
The first thing we need to do is start our python programming environment and import all the tools (libraries) we’ll be using during this project. For this project, we’ll be using 3 of the most popular python libraries: Requests, BeautifulSoup and Pandas.
import requests
from bs4 import BeautifulSoup
import pandas as pdThe requests library is generally used to send a message i.e. ‘make a request’, from a client to a host server. Every time we visit a web page, we make a type of request to a server. The BeautifulSoup library allows us to break down an HTML document (for example, a web page) into a ‘parse tree’, and allows us to navigate and search through that parse tree to dissect and extract what we need. We shall be using the Pandas library for exporting our data into a file.
The URL to the book store we wish to scrape data from is ‘books.toscrape.com‘.
STEP 1: REQUESTING
As mentioned, the first step involves sending a request to the webpage server and getting a response. To send this request, we need the GET method from the requests library. This GET method requests a representation of the resources on the web page and grabs all the content of the response to our request. We store this response in an object and call that object r.
base_url = 'https://books.toscrape.com/'
r = requests.get(base_url)STEP 2: PARSING
Next, we need to figure out a way to break down and dig into the contents of our response object. This is where the BeautifuSoup library comes in handy, to help us ‘parse’ (in other words, break down and examine) our object. With this, we can take a look at where within the tags of the website the content we are looking for is located.
soup = BeautifulSoup(r.content, 'lxml')The new soup object we created now contains the contents of the website we requested, broken down into its individual elements. We can get all the information we need from this new object.
Time to get our hands dirty within the soup and start our search.
The extracting part requires some basic knowledge of how HTML tags work to correctly identify the type of HTML tag and the unique tag name of the content we are looking for. For this, we inspect the page source of the online bookstore.
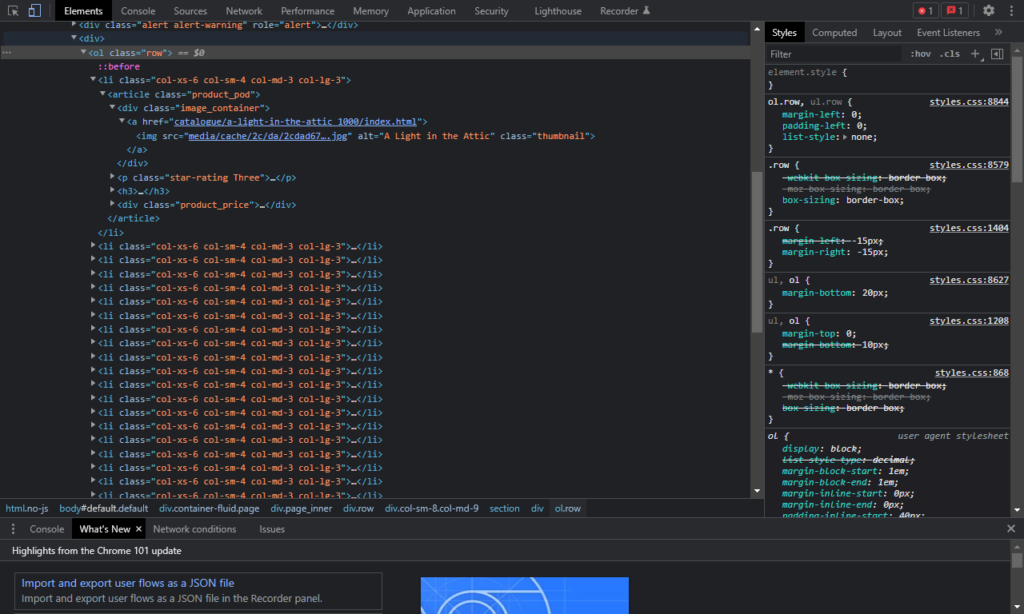
We want to extract the name of each book, the price and whether the book is currently in stock. Looking at the page source, these details can be found within an <article> … </article> tag for each book, with unique tag name poduct_pod. Calling BeautifulSoup’s find_all method on our soup object allows us to find all elements with the same name, in this case, all <article> element tags with the name product_pod, within our parse tree and extract them into a new object variable. We shall call our new object books.
books = soup.find_all('article', class_='product_pod')Within the books object lies all the information we need to extract for every book. By iterating through every object in our books list object, we can extract the text we need, once again by going back to the page source and paying attention to the HTML tags which nest the text we wish to collect. At the end of every iteration, we also need to store each text extracted into a data structure that can store values in a key::value pair for each book. The most appropriate data structure for this is a dictionary.
for book in books:
title = book.find('img', class_='thumbnail')['alt']
product_price = book.find('p', class_='price_color').text
stock = book.find('p', class_='instock availability').text.strip()
book_dictionary = {
'title': title,
'product_price': product_price,
'in_stock': stock,
}
book_list.append(book_dictionary)Almost done! All that’s left to do is collect and save our output into our required format.
STEP 3: SAVING OUTPUT
We have our list object called book_list, which contains key::value pair details about the name, price and availability for each book. All that’s left to do is to decide how we want to export our data and what type of output would work best. Since a .csv file format works fine to store our output, let’s export all the data extracted into a spreadsheet. . And this is where the Pandas library comes in handy. In less than 5 lines of code, we can convert our list object into a dataframe of rows and columns, and export the dataframe into a .csv file.
df = pd.DataFrame(book_list)
df.to_csv('bookstoscrape.csv')
print('Done!')Final Words
All done! With an understanding of python libraries, methods and functions, for loops and data structures, we were able to successfully build the most basic type of web scraper for a simple HTML website. A note of caution is important, as there are several real-world scenarios we didn’t account for while writing our script such as:
- How do we deal with all the other pages in the category without having to repeatedly change the URL in our script?
- How do we account for exceptions and unexpected syntax errors which may occur?
- How can we clean our script into functions, so it is reusable for other related tasks?
Web scraping is a great way to be introduced into the world of building and automating tasks but it isn’t always this simple. In practice, the constraints may well be beyond our skill as a developer. Some websites do not like the details on their websites scraped because they want to manage the number of requests their server handles at a time (to avoid server downtime). Sometimes, the details we wish to scrape are behind a paywall or a log-in page, to verify the identity of the person making the request (for example, emails). The web page may also be dynamic, rather than static like the simple HTML page we used, which would make building the web scraper trickier. All these constraints are worth considering during the process of pseudo-coding ie before you begin writing your script. The most important takeaway to remember is that automating the process of web scraping, regardless of the constraints, always follows 3 broad categories: first we make our request, we parse the contents of the webpage and extract the information we need, and finally, we save our output.